This latency exists with all work units on my system. Generally pausing the CPU fold will decrease the GPU TPF by about 10% on any given WU.ThWuensche wrote:As for the PPD, I don't care much. What I care about is the volume of calculations required to support scientific results. I just bought another PC and two more Radeon VII to support the scientific results (not the PPD). As I understand the support of project moonshot will need a lot of computational power and it's sad if big part of it stays unused (for the electricity bill it's good, but ...)
What I conclude from the observations from Crawdaddy and BobWilliams supports the second of the reasons mentioned above, latency in interaction with the CPU. For a low end GPU, the GPU is limiting and not the interaction with the CPU, for a high end GPU, the interaction with the CPU becomes limiting. Thus latency would be a big show-stopper for high-end GPUs, but mostly go by unnoticed on smaller GPUs. The latency issue seems also confirmed from Crawdaddy's test with stopped CPU folding. The low memory footprint I observed is good for GPUs with limited memory and memory bandwidth, but leaves the benefit of the 16G fast RAM on the Radeon VII unused. So bigger work packages and less interaction might help to make good use of high-end GPUs (if that is possible from the nature of the WUs). Don't know about behaviour of the bigger NVidia GPUs in this situation, any ideas?
Here is the results of an 11762 WU:
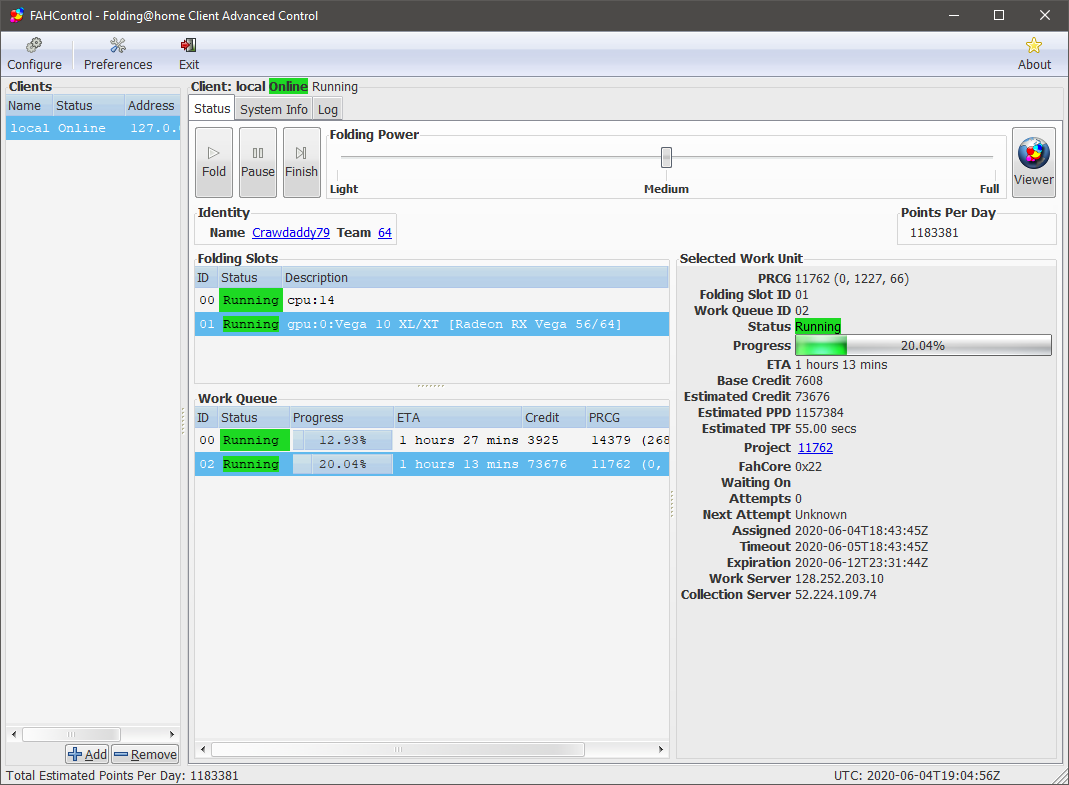
CPU Unpaused, GPU nets 1.25M PPD: Image
{kind=link}
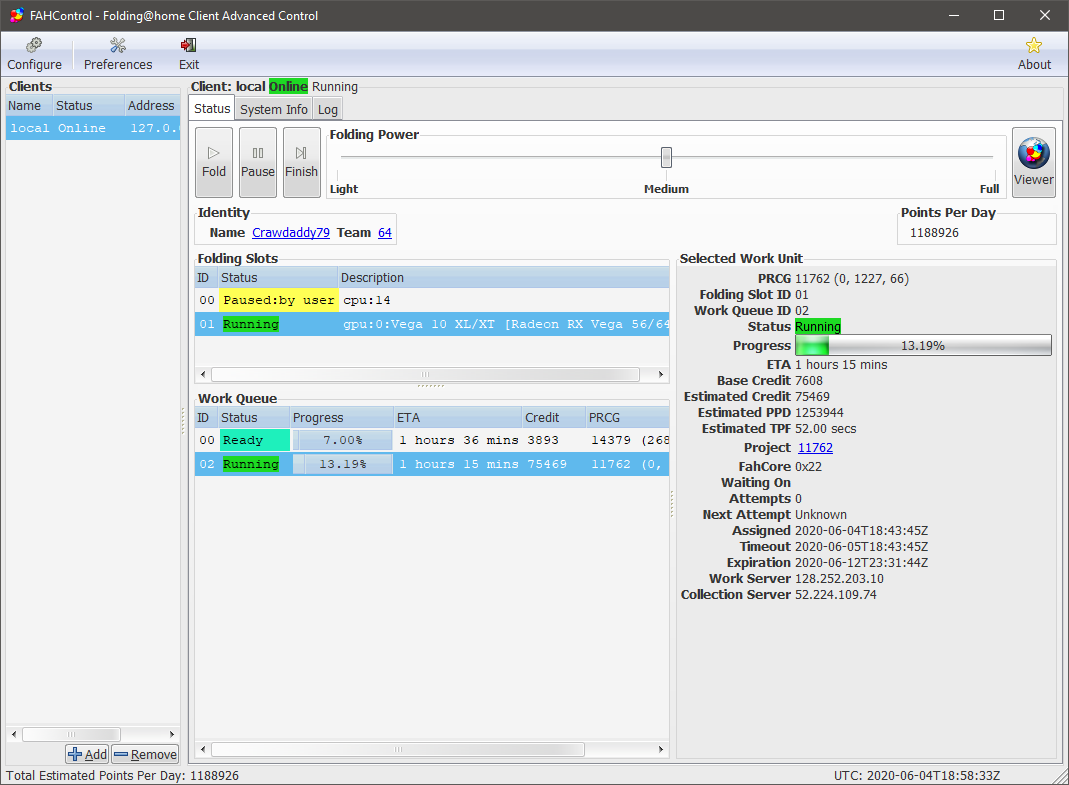
CPU Paused, GPU nets 1.15M PPD: Image
{kind=link}
It costs more GPU points than the CPU earns when using both simultaneously - this will vary by architecture.