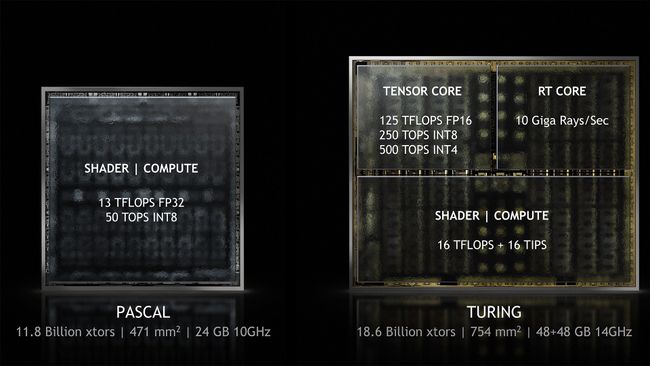
If F@H could use FP16, Int8 or Int4, it would indeed speed up the simulation.
Sadly, even FP32 is 'too small' and sometimes FP64 is used. Always using FP64 would be ideal, but it is just too slow. (Some cards may do FP64 32 times as slow as FP32)
As the simulation Programs (mostly OpenMM for GPUs) get updated with Volta and Turing in mind I would expect the developers to make use of them in scenarios where the errors do not accumulate. I have my doubts there are any such subroutines in OpenMM.
As examples, here is a wikipedia page on Nvidia GPUs, I started with Pascal, but you can scroll up for older micro-architectures. Wikipedia calls FR32 Single Precision, FP64 Double Precision, and FP16 Half Precision.
https://en.wikipedia.org/wiki/List_of_N ... _10_series
You will notice that Pascal supports Half Precision, but very slowly. It would not be useful to modify Pascal Code. Volta is very fast at both Double Precision and Half Precision, it would make a great F@H micro-architecture (because Double Precision or FP64 is very fast) but is VERY expensive. Turing does Half Precision very rapidly, but not Double Precision very fast. (Even the slowest Volta is 10 times as fast as the fastest Turing at Double precision)
FP16 is going to be most useful when you never plug the results of one equation into the inputs of the next equation. Modeling Proteins does a great deal of plugging the results of one time frame into the inputs of the next time frame.
Again, I have no reason to suspect F@H can use Half Precision, I suspect it would cause rounding errors that would overwhelm the simulation.